


Welcome to the Clements Texas Project metadata tutorial!
We’re proud of the metadata we’re creating for the Clements Texas Papers! When the project is complete, our project staff will have meticulously compiled individual metadata profiles for each of over 14,000 digital records in this collection. In fact, we view our metadata as one of this project’s most significant intellectual contributions. We hope that it will help casual users of our site learn more about Governor Clements and his era, and that researchers will be able to draw out new insights from patterns hidden in the archival text.
To understand why we’re putting so much work into our metadata—and what you can do with it—it helps to be familiar with what metadata is and how it works. This short guide will introduce some of the basic concepts behind metadata, a description of how we use it on this site, and a few tips on how to harness the power of our metadata for your own research.
What is it?
Metadata is typically defined as “data about data.” Although the term itself was coined relatively recently, people have applied the concept of metadata for thousands of years to organize, describe and retrieve recorded information. Metadata is ubiquitous. Think of any book on your shelf: its title, author, or even the paper stock used in your particular copy. Each of these bits of information is an example of metadata, and each is helpful for describing your book as an object, i.e., a discrete piece of knowledge.
Not coincidentally, metadata is at the heart of library and archival science. Professionals in these fields generally divide metadata into three or four basic types. Descriptive metadata is used for discovery and identification, and usually contains elements like title, author, or keywords. Structural metadata tells us how the various parts of an object fit together, such as page and chapter order. And finally, administrative metadata describes the management of a resource, including provenance, ownership and rights management, and the technical features of an object. (Some specialists, however, consider technical metadata to be its own distinct category.) The latest NISO standards also include markup languages as a major metadata type. The latest NISO standards also include markup languages as a major metadata type. Markup languages like HTML and XML integrate metadata and flags for structural and semantic features into actual content, improving navigation and increasing interoperability.
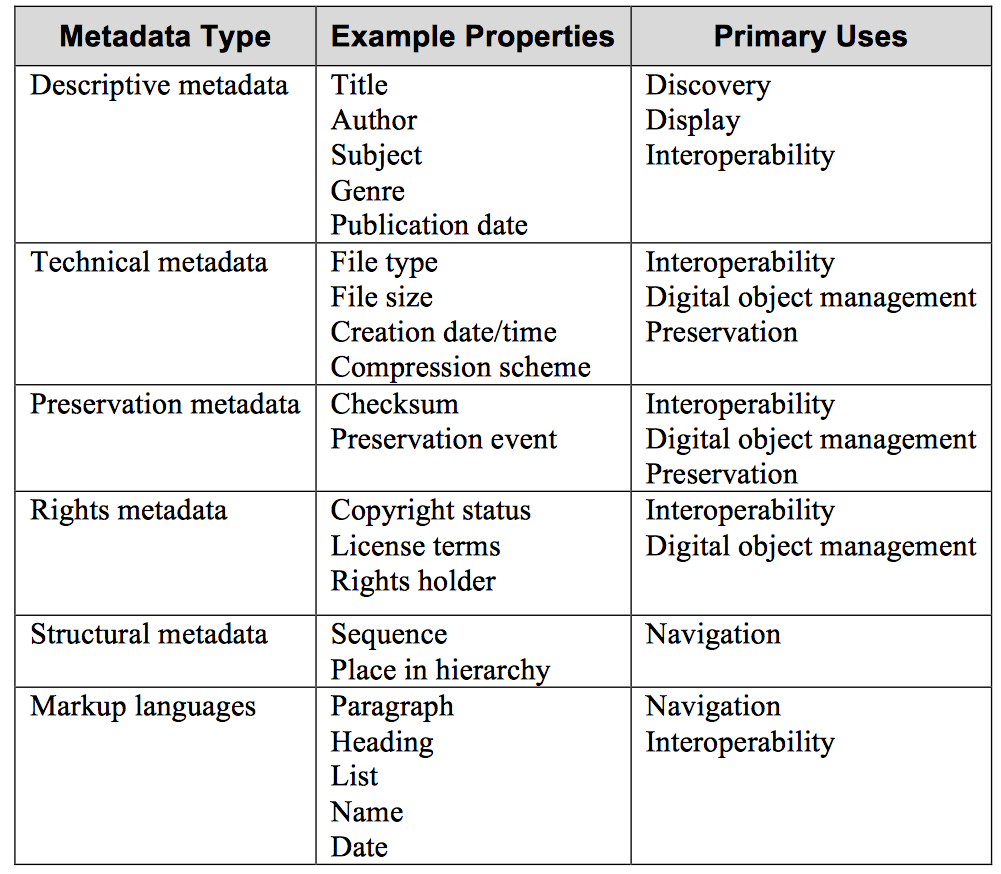
Figure 1: Metadata Properties and Uses (from Understanding Metadata, Jenn Riley, NISO 2017)
Metadata in the Clements Texas Papers
In the context of a digital collection like the Clements Texas Papers, metadata functions as a parallel—but distinct—corpus of material that describes the objects in the actual digital collection. It is constructed information, crafted by people rather than extracted directly from the digital objects themselves. “Good” metadata generally does four things:
- It conforms to community standards in a way that is appropriate to the collection;
- It supports interoperability, making it possible to exchange and use metadata information across different platforms, data structures and interfaces;
- It uses consistent forms of descriptive terms (authority control and content standards) to help users discover and access exactly the records they want;
- It includes a clear statement of the conditions and terms of use for digital objects.
These objectives serve as benchmarks for Briscoe staff, and have guided our approach since the project’s conception.
The Briscoe Center for American History uses the Metadata Object Description Schema (MODS) to describe the content in our digital collections. MODS is a hybrid bibliographic description schema, drawing elements from the more complex and unwieldy MARC format, while retaining the basic structure of the simple and easy-to-use Dublin Core standard. The MODS schema is an example of what metadata practitioners refer to as a uniform standard. Through MODS, the metadata on the Clements Texas Papers site is made syntactically and semantically “interoperable” with metadata from other digital archives and libraries, which use similar semantic frameworks to describe their own resources. As more and more digital projects conform to the same uniform standards, interoperability makes it possible for users to explore numerous digital libraries and archives using the same search values. And because our metadata records are machine-readable through XML markup language, it can also be exported directly to other software platforms, including word processors, spreadsheet and database tools, mapping and analytics software, translation and bibliographic programs, etc.
When you search and then click on an object in the Clements Texas Papers collection, you will see a high-resolution image of the object, and a metadata description including the following possible elements:
- Identifier: This field contains the unique, standardized code or number that distinctively identifies a resource.
- Title: This field contains the name by which an object is formally known.
- Creator/Contributor:* This field describes the person, organization or family associated with the creation of an object, and their role in its creation.
- Coverage:* This field describes the time period and/or geographic scope of a resource.
- Themebook: If a resource is associated with one of the themebook categories listed on the main page of the site, that category will be listed in this field.
- Subject Name:* This field contains the term(s) or phrase(s) representing the primary topic(s) on which a resource is focused.
- Genre:* This field describes the resource type (e.g. letter, report, memo, etc.)
- Topic:* This field contains standardized keywords that describe the contents of the resource.
- Description: This field is a succinct summary of the content of a resource.
- Notes: This field contains any information about a resource that the cataloger considers relevant that is not captured in other metadata fields.
- Language(s): This field identifies the language used in the resource.
- Related items: This field list items related in some way to the resource being described.
- Location information: This field describes where a digital resource can be found in the original physical collection.
- Usage rights: This field provides information about rights over the resource, and how it can be used, distributed, reproduced, etc.
Below is an example of an object in the Clements Texas Papers collection, along with its full metadata.
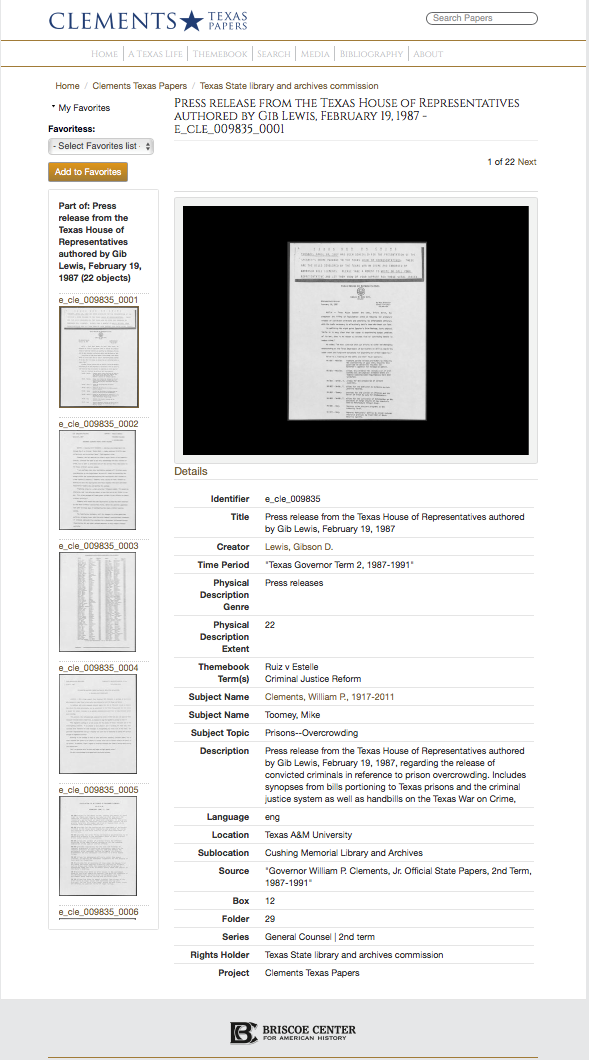
You may have noticed the asterisk next to many of the metadata fields listed above. These fields use what librarians and archivists call “authority controls.” Authority-controlled elements use pre-assigned and unique syntax to make sure that every name, topic, place, genre, etc. is cataloged consistently, exclusively, and unambiguously for every record in the collection. Archivists refer to this function as “disambiguation.” The collection is indexed by the terms contained in those fields, creating clickable “access points” for users to discover other materials in the collection containing the same contents. Each name, topic, place, genre, etc. is entered the metadata in precisely the same way every time, so that you can search for every other instance simply by clicking on that element.
How can metadata improve my searches?
Faceted searching
Almost all of the documents contained in the Clements Texas Papers are full text searchable because an Optical Character Recognition (OCR) text file has been created for every item. But the addition of thorough metadata allows you search the collection in ways that simply would not be possible using a keyword search alone. Let’s say, for example, that you are researching the War on Drugs, and wish to view the written correspondence between Governor Clements and President Reagan on that topic during Clements’ first term. Because every document in the Clements Texas Paper collection is searchable by keyword, you could simply type “Reagan,” “Clements” and “War on Drugs” into the search bar. But your search would retrieve every document containing both names somewhere in the text, regardless of time period, topic, or resource type. By employing an advanced, or “faceted,” search instead, you could query the collection’s metadata for every letter or memo created between 1978 and 1983, for which William Clements and Ronald Reagan are both credited as correspondents and “War on Drugs” is listed as a topic. Using these access points as “filters” increases the precision of your search results (i.e. the fraction of retrieved documents that are relevant) without reducing recall (i.e. the probability that a relevant document is retrieved by your query). If your search generates too many results, you can try using the advanced search options to narrow your results. Conversely, if your search generates too few results, you may wish to broaden your search criteria. As you browse the collection, you will find the facet-enabled search function at the left hand side of your screen.
Authority Control
The effectiveness of a faceted search is contingent upon the consistency and uniqueness of the terms used to describe the collection in the metadata. It can be frustrating to search a database, such as a library catalog, that uses several different names and spellings to categorize the same thing. Strict authority control allows for disambiguation of objects with similar headings. The Clements Texas Papers has created thousands of authority-controlled terms for users to search by, improving research efficiency, making searches more predictable, and slowing the accumulation of typos and misspellings in machine-readable data over time.
Authority control also makes it possible to extend a subject search beyond the bounds of one digital collection. Wherever possible, the Clements Texas Project has used preexisting authority controls managed by worldwide name authority services such as VIAF, Geonames and the Library of Congress, which are also used by thousands of other libraries around the world.
What can digitization and metadata tell me about this collection that I can’t find out through close reading and contextualization of the actual documents?
The digital humanities are a comparatively young and fast-moving field, and there is still spirited debate among its practitioners as to its boundaries and limitations, and about how the digitization of text can alter and enhance traditional humanities-oriented scholarship. Most researchers understand physical archives as repositories of documentary evidence. Digitization and high-quality metadata, however, can turn an archival collection into an analyzable dataset, with dizzying ramifications for what digital researchers can potentially discover. When complete, the Clements Texas Papers will allow researchers to download metadata for selected objects as .xml files, which that then be imported into a number of different data analysis tools freely available on the web.
Content Analysis/Text Mining
The digitization of archival text has made it possible, for example, to automate and scale up conventional research techniques like content analysis (i.e. the quantification and analysis of the frequency, meanings and relationships of words and concepts within a text (or set of texts) in order to make inferences about conditions of its creation.) Where scholars once had to laboriously count the appearance and frequency of certain words in a text, it is now a relatively simple matter to quantify and analyze the content of thousands of documents in short order, using specialized software tools developed for that purpose. There are many web-based text analysis tools, including Voyant, TokenX, Juxta, Tableau and Google Books Ngram Viewer. A more complete list of all of these tools can be found at the DIRT (Digital Research Tools) directory.
Network Analysis
Network analysis can be used to explore the relationships and connections within a dataset. It is a familiar methodology in the sciences, but digital collections like the Clements Texas Papers make it possible for humanists to employ this technique in their own work. In the humanities, network analysis can reveal the relationships between subjects, highlight social interconnectedness, or trace behavioral dynamics. There are a number of these tools as well, such as Heurist Data Manager/Visualizer and Onodo, among others.
Data Visualization
Data visualization refers to techniques used to communicate data or information as visual objects (e.g., points, lines, bars, maps, etc.) contained in graphics. Effective visualization allows users to quickly identify, observe, and postulate about the data and evidence contained in our digital collections. Researchers can export data from our website into various data visualization tools in order to make charts, graphs, and other visuals that elegantly describe and exhibit new insights into the contents of the archive, showing patterns and relationships that were previously hidden in the documentary evidence. For a more complete list of data visualization tools, check out DIRT’s list here.
TEI
The Text Encoding Initiative (TEI) is a consortium which collectively develops and maintains a standard for the representation of texts in digital form. Its chief deliverable is a set of Guidelines which specify encoding methods for machine-readable texts, chiefly in the humanities, social sciences and linguistics. Since 1994, the TEI Guidelines have been widely used by libraries, museums, publishers, and individual scholars to present texts for online research, teaching, and preservation. In addition to the Guidelines themselves, the Consortium provides a variety of resources and training events for learning TEI, information on projects using the TEI, a bibliography of TEI-related publications, and software developed for or adapted to the TEI. (Text taken from TEI website.)
Get in touch!
If you’re conducting a research project, planning an assignment, or writing a report for school, let us know what you’re doing, and how we’re doing!